Figure 1. Vision Module configuration.

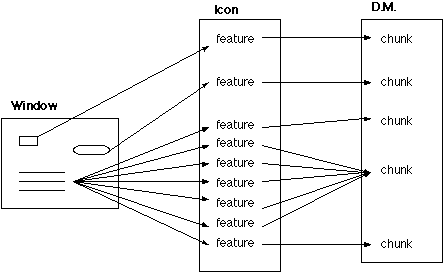
The Vision Module takes a window and parses the objects in that window. Each object will be represented by one or more features in the Vision Module's icon. These features are the basic units with which ACT-R interacts. Each feature contains information about what kind of screen object it represents, where it is, and so on.
The mapping from screen objects to icon features is not necessarily one-to-one. A screen object can create multiple features, depending on what that screen object is and how the Vision Module is configured. Most screen objects will generate one feature, the most common exception being anything containing text. Text will get parsed into multiple features. If, :OPTIMIZE-VISUAL is true (the default), then each word in the text will be parsed into one feature. Thus, long sentences will be parsed into many features. If :OPTIMIZE-VISUAL is false, then each letter is parsed into multiple features. The features consist of a LED-type representation of the characters of the text. The following shows a graphical representation of the features, the number values associated with each feature, the letter E made from the features, and an abstract-letter chunk representing the letter E.
- - 1 2 - - |\|/| 34567 | (letter-e - - 8 9 - - isa abstract-letter |/|\| 01234 | value "E" - - 5 6 - - line-pos (1 2 3 8 9 10 15 16))
The Vision Module creates chunks from these features which provide declarative memory representations of the visual scene, which can then be matched by productions. Generally, each icon feature maps to one chunk in declarative memory. The notable exception is again text. If optimizing is on, then the basic unit is words, though the Vision Module can be told to look for phrases. If optimizing is off, then the Vision Module can be told to look for letters, words, or phrases. Letters are synthesized from clusters of the LED-style features according to a Bayesian categorization algorithm to determine the best letter given a set of LED features.
For the Vision Module to create a chunk for an object, visual attention must first be directed to the location of that object. In order to do that, the Vision Module provides a command to move attention. The attention movement command requires a specification of a location to which to move. These locations exist as "virtual chunks" of type VISUAL-LOCATION. Whenever ACT-R requests a match of a chunk of type VISUAL-LOCATION and the "time now" flag is included in that test, ACT-R does not actually attempt to retrieve a chunk from declarative memory but instead calls the Vision Module. The Vision Module then checks the icon to see if there is a feature in the icon that matches the chunk requested by ACT-R. If one exists, a chunk representing that visual location is created and returned to ACT-R in zero time. If none exists, then the left-hand side of the production requesting the match will fail.
The chunk representing the visual location can then be passed back to the Vision Module along with a move attention command, which causes the Vision Module to shift attention to that location. If there is anything in the icon still at that location, then a chunk will be created which represents that object, and that chunk is considered the focus of attention (making it an activation source). If there is more than one object at the location moved to, then one of them will be picked randomly to be the focus of attention. These chunks are VISUAL-OBJECT chunks (or a subtype of VISUAL-OBJECT). The basic assumption behind the Vision Module is that the visual-object chunks are episodic representations of the objects in the visual scene. Thus, a visual-object chunk with the value "3" represents a memory of the character "3" available via the eyes, not the semantic THREE used in arithmetic--some retrieval would be necessary to make that mapping. Same thing with words and such. Note also that there is no "top-down" influence on the creation of these chunks; top-down effects are assumed to be a result of ACT's processing of these basic visual chunks, not anything that ACT does to the Vision Module.
Because the currently attended object chunk is an activation source, it should always be retrievable. However, there is no guarantee that when trying to retrieve a visual-object chunk that the current focus will be retrieved--there are probably lots of other visual-object chunks floating around in declarative memory. So a mechanism that allows ACT to discriminate between what it currently sees and the memory of things it has seen is again through the use of the "time now" flag. Including "time now" in a LHS clause matching a visual-object (or a subtype) will actually be translated into a call to the Vision Module rather than a true test of declarative memory. The Vision Module returns the chunk representing the current visual object, and the ACT-R pattern matcher decides if that chunk matches the specified pattern.
There is one more issue to consider, which is that of change. There are a couple issues with respect to change. First, what happens when the screen changes at the currently attended location? If the currently attended object changes, the system will mark the Vision Module as "busy" and will deliver a new chunk for what's there after the standard attention movement delay. Second, what happens when objects move? In general, nothing. However, the Vision Module can be told to track an object. When this happens, the currently attended location moves with the object, and the object's SCREEN-POS slot will be updated as the object moves.
When using the "time now" test for a VISUAL-LOCATION chunk, there are some special specifiers for the SCREEN-X and SCREEN-Y slots which the Vision Module understands:
VISUAL-OBJECT chunks have these slots:
SCREEN-POS is a pointer to the VISUAL-LOCATION chunk specifying where on the screen the object was seen. VALUE is some kind of content slot that will be filled in by the Vision Module. COLOR represents the color of the object. STATUS is a slot that initially contains NIL and can be used by ACT-R productions to annotate the chunk.
The most common task with the Vision Module is probably locating objects on the screen and attending to them. This simple production will cause the Vision Module to attend to something on the screen that has not been previously attended with the lowest x-coordinate:
(p attend-red
=goal>
...
=loc>
isa VISUAL-LOCATION
time now
attended nil
screen-x lowest
=mod>
isa MODULE-STATE
module :vision
modality free
==>
!send-command! :VISION move-attention :location =loc)
The move-attention command tells the Vision Module to move attention to the specified location, which is =loc. The test for a VISUAL-LOCATION with time now means that the current icon will be checked for a feature (rather than a chunk being retrieved). If such a feature exists, a chunk of type VISUAL-LOCATION will be created and will be bound to =loc. This chunk is then passed back to the Vision Module and attention is moved to that location.
After the Vision Module has shifted attention, if there is anything in that location, a chunk will be created that represents it, and the current visual focus will be on that chunk. If you wanted to know if the current thing being looked at is the word "foo" the test would look like:
(p looking-at-foo
=goal>
...
=obj>
isa VISUAL-OBJECT
time now
value "foo"
...)
For text, the string the text represents is passed back in the VALUE slot. The time now is necessary to discriminate this chunk--the one currently being looked at, from some memory of another "foo".
(p button-and-cursor-in-same-place
=goal>
...
=btn>
isa VISUAL-OBJECT
value OVAL
time now
screen-pos =loc
=loc>
isa VISUAL-LOCATION
kind CURSOR
time now
=state>
isa module-state
module :motor
modality free
...)
This production should only fire when there is an object in the current focus of attention, and that object is an oval (button), and when there is an cursor feature on the screen such that the location of that feature matches the location of the button.
(p move-to-it
=goal>
...
=loc>
isa VISUAL-LOCATION
attended nil
screen-x 40
screen-y 40
=mod>
isa MODULE-STATE
module :vision
modality free
==>
!send-command! :VISION move-attention :location =loc
=goal>
lastloc =loc)
Notice that this does not have a time now in the VISUAL-LOCATION test--if there's nothing at that location, then a test using time now will fail (which is another way this can be accomplished, see below). This will only work if there's already a chunk at that visual location. If there isn't, you can go this route:
(p move-to-it-2
=goal>
...
==>
=newloc>
isa visual-location
screen-x 40
screen-y 40
!send-command! :VISION move-attention :location =newloc
=goal>
lastloc =newloc)
Then, once the move has completed, you can check with this:
(p check-for-nothing
=goal>
...
lastloc =loc
=loc>
isa VISUAL-LOCATION
attended T
objects nil ;;; this is the key
=mod>
isa MODULE-STATE
module :vision
modality free
last-command move-attention
...)
This production will fire when the last thing done was a move attention and there's nothing at the location moved to.
Alternately, you can do this without using anything in the goal, and set up two productions, one of which does something when an object is present and one of which is a defualt. If you're concerned about the currently-attended location, whatever that may be, try this one:
(p something-present-at-current-loc
=goal>
...
=obj>
isa VISUAL-OBJECT
time now
=mod>
isa MODULE-STATE
module :vision
modality free
last-command move-attention
...)
which will fire if there's anything at the currently attended location.
However, if you want a specific location, whether it's currently attended or not, then if this production:
(p something-present-at-specific-loc
=goal>
...
=loc>
isa VISUAL-LOCATION
time now
screen-x 40
screen-y 40
==>
...)
will fire if there is anything at (40, 40) and fail if there isn't. Whichever method you use, then have a second production act as a default:
(p nothing-there
=goal>
...
=mod>
isa MODULE-STATE
module :vision
modality free
last-command move-attention
...)
This production will always fire, of course, but it is possible to get the desired behavior by making the something-present production preferred in conflict resolution.
First, some background on how RPM does this for the items it already handles. Simply, proc-screen walks the list of subviews for the experiment and calls the method build-features-for on each item it encounters. Method dispatching figures out what kind of object each subview is and the appropriate method is called for each subview. Thus, methods are currently defined for editable-text-dialog-items, button-dialog-items, and static-text-dialog-items. Thus, to extend processing of a screen to new types of items, all that is necessary is a build-features-for method for that class.
The recommended way of handling this is to define a new subclass of VIEW in which all drawing for your custom object is done. Then, you specialize a method of BUILD-FEATURES-FOR for this class of view. This method should return a list of icon-features. This class is defined in the file "vision-module.lisp," and has several subclasses: oval-feature, rect-feature, and line-feature. Buttons, for example, generate oval-features. Your object can be constructed out of these basic features, or, if necessary, you can define more subclasses of icon-feature. One thing you should not have to do, however, is write any code for generating features for text. To do that, simply call the build-string-feats method, also found in "vision-module.lisp."
An example might help. First, the feature in question are arrows, which can either point left or right. You'll need to define a class for the view which draws arrows (you'll also have to define a view-draw-contents method to actually have the arrow drawn on the screen. That's an exercise for the reader):
(defclass arrow-view (simple-view) ((direction :accessor direction)))You'll normally want a subtype of icon-feature to be put into the icon when the screen is processed:
(defclass arrow-feature (icon-feature)
((direction :accessor direction :initarg :direction))
(:default-initargs
:isa 'ARROW
:value 'ARROW
:dmo-id (gentemp "ARROW")))
Now, to actually have the system build such a feature when an arrow view is encountered, you need to define a build-features-for method, which generates a feature of that class:
(defmethod build-features-for ((self arrow-view) (vis-mod vision-module))
(let ((my-position (view-position self)))
(make-instance 'arrow-feature
:direction (direction self)
:x (point-h my-position)
:y (point-v my-position)
:attended-p nil)))
Of course, we could have made the arrow more complicated and constructed it out of, say, three lines (rather than making an arrow a basic visual feature). If you go that route, one common operation in drawing things on the screen is the use of MCL's line-to function. Rather than building line-features for all those lines yourself, you can call the function rpm-line-to instead. This will both draw the line and create a matching line-feature, adding that feature to the icon. Be sure that the experiment window has been set before calling this, or results can potentially be flaky.
[1] Create your subclass with visual-object as the default for the kind slot and whatever you want for the value slot. RPM will use the default feat-to-dmo method on your features to translate them into chunks of type visual-object. This approach is fairly limited but is simple.
[2] Along with your class of features, define a chunk type to represent objects of this feature class and :include the visual object chunk in that definition. Be sure the kind slot in your feature objects matches the name of the chunk type you defined. You will then need to write a feat-to-dmo method for your feature class which translates feature objects into declarative memory objects. (Declarative memory objectsŃor DMO'sŃare how RPM understands chunks. Creating DMO's also creates ACT-R chunks.) Probably the best way to do this is use call-next-method to get the default slots (e.g. location, kind) set and then use set-attribute on the result to set the remaining slots. To go back to the arrow example, you'll need a chunk type which encodes an arrow:
(chunk-type (arrow (:include visual-object)) direction)There needs to be a method for going from a feature to a chunk (this happens when move attention is called on the location at which the feature resides), which is a feat-to-dmo method:
(defmethod feat-to-dmo :around ((self arrow-feature))
(let ((the-chunk (call-next-method)))
(set-attribute the-chunk `(direction ,(direction self)))
the-chunk))
This is a little tricky, since it's an :around method that knows what the default feat-to-dmo method does, which is note that this feature has been attended, generate a DMO representing the object, and return that DMO. The :around method just takes the returned DMO and modifies it. The base method is this:
(defmethod feat-to-dmo ((feat icon-feature))
"Build a DMO for an icon feature"
(setf (attended-p feat) t)
(make-dme (dmo-id feat) (isa feat)
`(screen-pos ,(id (xy-to-dmo (xy-loc feat) t))
value ,(value feat)
color ,(color feat))
:obj (screen-obj feat)
:where :external))
If you don't want to mess with :around methods, you could just write it like this:
(defmethod feat-to-dmo ((feat arrow-feature))
"Build a DMO for an arrow icon feature"
(setf (attended-p feat) t)
(make-dme (dmo-id feat) (kind feat)
`(screen-pos ,(id (xy-to-dmo (xy-loc feat) t))
value ,(value feat)
color ,(color feat)
direction ,(direction feat))
:obj (screen-obj feat)
:where :external))
I don't do it that way just because it's a lot of redundant code, but you can do it however you like.
Your methods can also be more complicated, and construct DMO's out of collections of features. This is how RPM handles text, for instance. If you need help doing this, please contact me (Mike) directly.